Unsupervised Learning
In today’s data-rich world, the phrase Unsupervised Learning is becoming increasingly important. Whether you’re a data scientist, a business decision maker, or a curious learner, understanding Unsupervised Learning helps you unlock insights from raw data without the need for predefined labels. Additionally, if you are looking for specialised training, you might consider “generative ai training in Hyderabad”, which often covers Unsupervised Learning as a key topic. In this article, we’ll explore What is Unsupervised Learning?, the Key Differences Between Supervised and Unsupervised Learning, the Common Techniques in Unsupervised Learning, and real-world Applications of Unsupervised Learning.
What is Unsupervised Learning?
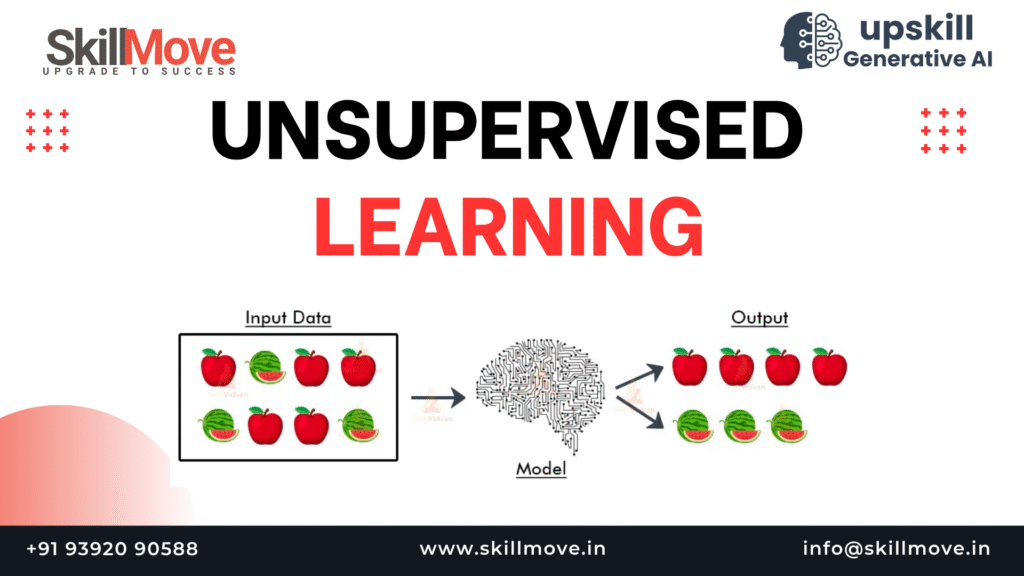
In the rapidly expanding world of Artificial Intelligence (AI) and Data Science, one concept has become increasingly vital — Unsupervised Learning. It is a type of machine learning that allows algorithms to discover hidden patterns, groupings, and structures within data without any human-provided labels or outputs.
Unlike supervised learning, where models are trained on input–output pairs, Unsupervised Learning works only with raw, unlabeled data. The model’s task is to make sense of it independently — finding relationships, correlations, or clusters that humans might not immediately notice.
In simple terms, Unsupervised Learning teaches computers to “see” structure in chaos.
Real-World Context
Think about the immense volume of data generated daily — social media interactions, customer transactions, website logs, sensor readings, and more. Most of this data is unlabeled, meaning we don’t know in advance which category or class each record belongs to.
This is where Unsupervised Learning becomes powerful. It enables systems to explore, analyze, and interpret data in ways that reveal previously unknown insights — which is one reason it’s taught extensively in Generative AI Training in Hyderabad programs, where students learn to handle unlabeled data for generative modeling and clustering tasks.
Definition
Formally, Unsupervised Learning is a machine learning approach in which models are trained on datasets without labeled responses. The algorithm observes patterns and structures in the input features and tries to organize or summarize the data based on internal similarities.
Mathematically
If X={x1,x2,…,xn}X = \{x_1, x_2, …, x_n\}X={x1,x2,…,xn} represents input data with no labels, an Unsupervised Learning algorithm aims to learn:
- A function f(X)f(X)f(X) that groups similar data points (clustering), or
- A function g(X)g(X)g(X) that projects data into lower-dimensional spaces while retaining meaningful variance (dimensionality reduction).
How It Works — Step by Step
- Data Collection:
Gather large amounts of unlabeled data (e.g., customer data, sensor readings, documents). - Feature Extraction:
Convert raw data into meaningful numeric or vector representations. For example, images are converted into pixel intensity vectors; text into embeddings. - Algorithm Selection:
Choose an appropriate Unsupervised Learning algorithm — clustering (like K-Means), dimensionality reduction (like PCA), or association rule mining (like Apriori). - Pattern Discovery:
The algorithm identifies hidden patterns or structures. For example, similar customers may fall into one cluster, while distinct ones form separate clusters. - Result Interpretation:
Since there are no predefined labels, the results must be interpreted by humans or validated using domain expertise. - Utilization:
Insights from Unsupervised Learning can feed into other AI tasks such as anomaly detection, recommendation systems, or even Generative AI Training in Hyderabad where students apply them to autoencoder or GAN projects.
Key Characteristics of Unsupervised Learning
| Characteristic | Description |
|---|---|
| Input Data | Only input variables; no labels or outcomes are provided. |
| Goal | To discover hidden patterns, clusters, or latent structures in the data. |
| Human Intervention | Minimal — model works independently to detect patterns. |
| Output Type | Groupings (clusters), lower-dimensional data, or associations. |
| Evaluation | More subjective; requires interpretive or statistical validation (e.g., silhouette score). |
| Use-cases | Customer segmentation, anomaly detection, image grouping, etc. |
Types of Unsupervised Learning
There are two primary types of Unsupervised Learning based on purpose:
Clustering
Used to group similar items together. Example algorithms include:
- K-Means
- Hierarchical Clustering
- DBSCAN
Clustering helps businesses segment customers or analyze patterns in social media behaviour.
Association
Used to discover relationships between variables. Example:
Apriori Algorithm for “market basket analysis” — finding frequent item sets like {bread, butter} → jam.
Dimensionality Reduction
Techniques like PCA (Principal Component Analysis) and t-SNE reduce complex data into smaller sets of features while preserving structure. These are extremely valuable in visualization, noise reduction, and preprocessing for Generative AI Training in Hyderabad.
Why Unsupervised Learning is Important
- Real-World Data Is Unlabeled
In industries like healthcare, e-commerce, and finance, most datasets are unlabeled. Unsupervised Learning helps organizations utilize that data efficiently. - Reveals Hidden Patterns
It can discover customer segments, fraud patterns, or behavioural insights that humans might overlook. - Feature Extraction for Generative Models
Many Generative AI Training in Hyderabad modules rely on Unsupervised Learning for pretraining autoencoders or self-supervised models. - Cost-Efficient
Labeling data is expensive and time-consuming. Unsupervised methods eliminate the need for manual annotation. - Exploratory Data Analysis (EDA)
Unsupervised Learning acts as an exploratory tool to understand data distribution before applying supervised techniques.
Understanding Through a Real-World Scenario
Imagine you own an online retail business with 50,000 customers but no prior knowledge of their purchasing patterns.
You collect features like:
- Number of purchases per month
- Average order value
- Categories bought
- Time spent per session
You can apply Unsupervised Learning using the K-Means algorithm:
The algorithm automatically groups customers into clusters like:
- Cluster 1: Budget-conscious buyers
- Cluster 2: Luxury repeat customers
- Cluster 3: Occasional impulse buyers
Now, your marketing team can customize campaigns for each cluster.
This is a direct benefit of Unsupervised Learning — and exactly what students practice in Generative AI Training in Hyderabad, where similar clustering techniques are used on image or text datasets before generative modelling.
Key Differences Between Supervised and Unsupervised Learning
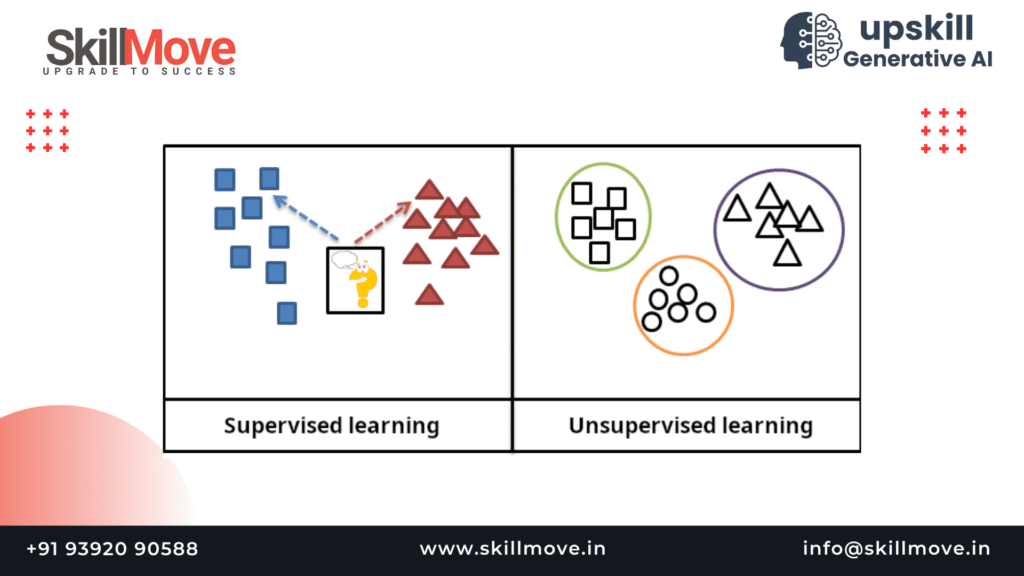
Understanding the distinction between Supervised and Unsupervised Learning is fundamental for anyone starting their journey in Artificial Intelligence or Machine Learning. Both are powerful techniques, but they serve different purposes depending on the nature of your data and the type of outcome you expect.
In Supervised Learning, you train a model using labeled data, where both inputs and their correct outputs are provided. In contrast, Unsupervised Learning deals with unlabeled data — it must discover the underlying structure all by itself.
This section will explore these differences in depth, helping you understand when and why you might choose one over the other — an essential concept covered in Generative AI Training in Hyderabad programs.
1. The Core Idea Behind Each Approach
| Category | Supervised Learning: Learning with Guidance | Unsupervised Learning: Learning Without Guidance |
|---|---|---|
| Definition | Supervised Learning is like teaching a student with a textbook full of answers — the model learns from labeled data (input X and output Y). | Unsupervised Learning uses unlabeled data; the algorithm explores and discovers hidden patterns or structures without guidance. |
| Learning Approach | Learns to map inputs to outputs by minimizing prediction errors. | Learns to group or organize data based on similarity, density, or hidden relationships. |
| Example | A spam-filtering model trained on labeled emails (spam / not spam) learns to classify new emails correctly. | Clustering customers into different market segments without prior category knowledge. |
| Data Type | Labeled data (both input and correct output provided). | Unlabeled data (only input features, no target labels). |
| Goal | Focused on prediction – predicting outcomes or categories. | Focused on discovery – finding patterns, groups, or latent features. |
| Common Algorithms | Linear Regression, Logistic Regression, Decision Trees, Random Forests, Support Vector Machines (SVM), Neural Networks. | K-Means Clustering, Hierarchical Clustering, DBSCAN, PCA (Principal Component Analysis), Autoencoders, Association Rule Mining. |
| Output | Predicts a label or continuous value based on training data. | Produces clusters, associations, or reduced dimensions. |
| Human Involvement | Requires significant supervision (labels provided by humans). | Minimal supervision; model identifies structure on its own. |
| Evaluation | Easy to evaluate using metrics like accuracy, precision, and recall. | Harder to evaluate — often assessed through interpretability or internal metrics. |
| Focus Area | Used when outcomes are known and prediction is required. | Used when structure or insight is unknown and needs discovery. |
| End Objective | To predict future or unseen outcomes based on training. | To reveal hidden patterns and understand relationships in data. |
2. Main Comparison Table
| Feature | Supervised Learning | Unsupervised Learning |
|---|---|---|
| Data Labels | Requires labeled datasets with input-output pairs. | Uses unlabeled datasets with only inputs. |
| Primary Goal | Predict outcomes accurately. | Discover hidden structure, relationships, or patterns. |
| Output Type | Continuous (regression) or categorical (classification). | Clusters, associations, or lower-dimensional data. |
| Human Supervision | High – labels provided by humans. | Low – algorithm learns on its own. |
| Evaluation Metrics | Accuracy, precision, recall, F1-score. | Silhouette score, Davies-Bouldin index, variance explained. |
| Example Algorithms | Linear Regression, Decision Trees, SVM, Neural Networks. | K-Means, PCA, Apriori, Autoencoders. |
| Applications | Sentiment analysis, fraud detection, price prediction. | Market segmentation, anomaly detection, data compression. |
| Cost | Costly due to labeling effort. | Cheaper, as it needs only raw data. |
| Interpretation | Easier – has ground truth to compare. | Harder – results may need human validation. |
3. The Learning Process — Step-by-Step Comparison
| Step | Supervised Learning | Unsupervised Learning |
|---|---|---|
| Example Dataset | Customer transaction data from an e-commerce site with features like number of purchases, average order value, session time, and product categories bought plus a label such as “Will the customer buy again? (Yes/No)”. | Same dataset without labels — only features like number of purchases, order value, and session time. |
| Learning Objective | Predict the labeled outcome (e.g., “Will the customer buy again?”). | Discover hidden patterns or groupings among customers. |
| Process Flow | Input → Output mapping: f(X) → Y Model learns to minimize the error between predicted output (Ŷ) and actual output (Y). | Algorithm analyzes data similarity and density to group related customers together. |
| Algorithm’s Task | Learn a mapping function that best predicts Y from X. | Identify internal structure and relationships within X. |
| Example Result | Model predicts whether a new customer will repurchase or not. | Model generates clusters, e.g.: • Cluster 1 – High-value frequent buyers • Cluster 2 – Occasional shoppers • Cluster 3 – Low-spenders |
| Evaluation Metric | Accuracy, precision, recall, F1-score, etc. | Silhouette score, cluster purity, or visual interpretability. |
| Human Involvement | High – requires labeled data and explicit evaluation. | Low – algorithm autonomously explores data patterns. |
| Outcome Type | Predictive (known output). | Exploratory (discover unknown structure). |
| Practical Application | Helps forecast customer retention or sales probability. | Helps segment market and personalize campaigns based on clusters. |
| Use in Training | Teaches models how to predict specific outcomes. | Teaches models how to discover insights from raw data, a major focus in Generative AI Training in Hyderabad programs. |
4. Use-Case Comparison in Real Life
| Domain | Supervised Learning Example | Unsupervised Learning Example |
|---|---|---|
| Finance | Predict credit risk or loan approval. | Detect abnormal transactions (fraud). |
| Healthcare | Predict disease likelihood based on symptoms. | Group patients with similar medical histories. |
| Marketing | Forecast sales based on campaigns. | Segment customers by purchasing behaviour. |
| Retail | Predict next purchase or recommend product. | Discover product associations in baskets. |
| Generative AI | Train model on paired input-output data (e.g., text → image). | Train models to learn latent representations for image generation. |
5. Strengths and Weaknesses
| Category | Supervised Learning | Unsupervised Learning |
|---|---|---|
| Strengths | • High predictive accuracy when labels are reliable. • Performance can be evaluated quantitatively using metrics like accuracy, precision, or recall. • Excellent for forecasting and decision-making tasks. | • Works effectively with unlabeled, real-world data. • Reveals hidden patterns or structures that supervised models may overlook. • Ideal for exploratory data analysis and feature discovery. • Forms the foundation for Generative AI systems, which is why it’s a key part of every Generative AI Training in Hyderabad curriculum. |
| Weaknesses | • Requires large, accurately labeled datasets. • Labeling data can be time-consuming and expensive. • May struggle with unseen data due to overfitting risk. | • Harder to evaluate performance objectively (no ground truth). • Results may lack interpretability and require domain knowledge. • Sensitive to parameter tuning (e.g., number of clusters in K-Means). |
6. Relationship Between Supervised and Unsupervised Learning
Although they appear different, both types can complement each other.
How They Work Together
- Preprocessing: Use Unsupervised Learning (like PCA) to reduce dimensionality before applying supervised models.
- Feature Engineering: Autoencoders (an unsupervised neural network) learn compact representations that improve supervised learning accuracy.
- Semi-Supervised Learning: Combines both — a small portion of labeled data guides the learning of a large unlabeled dataset.
- Generative AI: Many generative models (e.g., GANs, VAEs) use unsupervised or self-supervised methods to learn the underlying data distribution.
This synergy is why many industry-ready programs such as Generative AI Training in Hyderabad teach both together, emphasizing how unsupervised methods prepare and enhance supervised models.
7. Example – Linking Both Worlds
Let’s take an example from Generative AI:
- Unsupervised Step:
A model uses Unsupervised Learning to learn the latent space of faces — it understands variations in eyes, nose, smile, etc., without labels. - Supervised Step:
Then, using labeled data, another model learns to map certain attributes (like “smiling” vs “not smiling”) to generate new images accordingly.
This integration showcases how unsupervised pretraining provides the foundation for powerful AI applications.
8. Key Takeaways
- Supervised Learning → learns from labeled data to predict outcomes.
- Unsupervised Learning → learns from unlabeled data to discover structure.
Both can work hand-in-hand — Unsupervised Learning often comes first to uncover patterns, then supervised models refine predictions.In modern AI pipelines, especially in Generative AI Training in Hyderabad, both methods are taught together to give learners a complete understanding of how data evolves from chaos to intelligence.
Common Techniques in Unsupervised Learning
Unsupervised Learning is not a single algorithm but a broad category of machine-learning methods that work with unlabeled data.
The aim is to uncover structure, relationships, and meaning hidden within raw information — without any predefined outcomes.
These techniques help data scientists find clusters, reduce dimensionality, detect anomalies, and reveal associations that power modern analytics and Generative AI Training in Hyderabad courses.
Below are the most important five techniques of Unsupervised Learning that every AI professional should understand.
1. Clustering Algorithms
Definition
Clustering is the process of grouping similar data points together so that items in the same group (cluster) are more similar to each other than to those in other groups.
In simple terms, clustering answers the question:
“Can we discover natural groupings inside our data?”
| Algorithm | Description | Common Use Cases |
|---|---|---|
| K-Means Clustering | Partitions data into K clusters by minimizing within-cluster variance. | Customer segmentation, image compression, document clustering. |
| Hierarchical Clustering | Builds a tree (dendrogram) by merging or splitting clusters successively. | Gene expression analysis, topic grouping, social-network analysis. |
| DBSCAN (Density-Based Spatial Clustering) | Groups points densely packed together; identifies noise and outliers separately. | Fraud detection, anomaly identification, geospatial data grouping. |
Workflow
- Select number of clusters (K) or density parameters.
- Compute distance (similarity metric like Euclidean or cosine).
- Group points based on similarity.
- Interpret results using visual tools such as scatter plots or t-SNE.
Example Scenario
In a retail dataset, Unsupervised Learning through K-Means might form three clusters:
- Cluster 1 – High-value repeat buyers
- Cluster 2 – Budget-shoppers
- Cluster 3 – Occasional visitors
This helps marketing teams personalize offers and is a common practical exercise in Generative AI Training in Hyderabad classes.
2. Dimensionality Reduction Techniques
Definition
Real-world data often has dozens or even thousands of features.
Dimensionality Reduction simplifies these datasets by projecting them onto lower-dimensional spaces while preserving their core patterns and variance.
Why It Matters
- Makes data visualization and interpretation easier.
- Reduces computational cost for training AI models.
- Removes noise and redundant features.
- Improves accuracy of subsequent supervised or generative models.
Key Algorithms
| Algorithm | Description | Common Use Cases |
|---|---|---|
| K-Means Clustering | Partitions data into K clusters by minimizing within-cluster variance. | Customer segmentation, image compression, document clustering. |
| Hierarchical Clustering | Builds a tree (dendrogram) by merging or splitting clusters successively. | Gene expression analysis, topic grouping, social-network analysis. |
| DBSCAN (Density-Based Spatial Clustering) | Groups points densely packed together; identifies noise and outliers separately. | Fraud detection, anomaly identification, geospatial data grouping. |
Use in Generative AI
Autoencoders and variational autoencoders (VAEs) apply dimensionality reduction to learn latent representations of images or text, forming the foundation of many models taught in Generative AI Training in Hyderabad.
3. Association Rule Learning
Definition
Association Rule Learning discovers interesting relationships (correlations) among variables in large datasets.
It is used to find rules like “If X happens, Y is likely to happen too.”
Example
A supermarket’s Unsupervised Learning system finds:
If customers buy bread and butter, they often buy jam.
| Algorithm | Description | Example Use |
|---|---|---|
| Apriori Algorithm | Generates frequent item sets and extracts association rules using support and confidence thresholds. | Market-basket analysis, cross-selling. |
| FP-Growth | Faster alternative to Apriori; constructs a compact FP-tree to identify frequent patterns efficiently. | Recommendation systems, web usage mining. |
Metrics Used
- Support: How frequently an item appears in transactions.
- Confidence: Probability of Y given X.
- Lift: Strength of association relative to random chance.
This technique is often introduced in Generative AI Training in Hyderabad under the topic of “data-driven decision systems”.
4. Anomaly Detection / Outlier Detection
Definition
Anomaly Detection identifies rare events or observations that differ significantly from the majority of data.
It’s a core part of many Unsupervised Learning and cybersecurity applications.
Key Approaches
- Statistical Methods: Z-score, IQR, probability distributions.
- Clustering Based: Detect points that don’t fit well into any cluster.
- Distance Based: Use k-NN to find points far from others.
- Autoencoder Reconstruction Error: If a point is poorly reconstructed, it may be an anomaly.
| Domain | Example |
|---|---|
| Finance | Credit-card fraud detection. |
| Manufacturing | Fault detection using sensor data. |
| Cybersecurity | Network intrusion detection. |
| Healthcare | Identifying abnormal patient records. |
Unsupervised Anomaly Detection is also used in Generative AI Training in Hyderabad labs for data cleaning and model robustness testing.
5. Feature Learning / Representation Learning
Definition
Feature Learning focuses on allowing algorithms to automatically discover useful representations or features from raw data — rather than hand-engineering them.
This approach is especially vital in deep learning and Generative AI where massive unlabeled datasets exist.
Popular Techniques
| Method | Description | Example Use |
|---|---|---|
| Autoencoders | Learn to encode and decode data efficiently to capture important patterns. | Image denoising, feature compression. |
| Self-Organizing Maps (SOMs) | Map high-dimensional data onto low-dimensional grids for visual clustering. | Visualization of customer segments. |
| Restricted Boltzmann Machines (RBMs) | Stochastic neural nets that learn probabilistic distributions of input data. | Pretraining for deep networks. |
Why It Matters
Feature Learning is the bridge between Unsupervised Learning and Generative AI.
By learning latent representations of data, models gain the ability to generate new content, detect patterns, and understand context without explicit labels.
This concept is deeply integrated in Generative AI Training in Hyderabad, where learners train autoencoders and GAN models for image and text generation.
Applications of Unsupervised Learning
Unsupervised Learning plays a critical role in how modern organizations and AI systems analyze, interpret, and make use of unlabeled data.
From discovering customer segments to detecting anomalies and generating synthetic content, the applications of Unsupervised Learning span almost every industry.
In this section, we’ll explore the most powerful and widely used real-world applications of Unsupervised Learning — many of which are directly taught in Generative AI Training in Hyderabad programs.
1. Customer Segmentation and Marketing Optimization
Overview
Businesses accumulate vast amounts of customer data — demographics, purchase history, online activity, and feedback. Most of this information is unlabeled, making it ideal for Unsupervised Learning techniques like clustering.
How It Works
- Use K-Means or Hierarchical Clustering to group customers by similarity.
- Each group (cluster) reveals shared buying patterns or behavior.
- The marketing team can then personalize offers, discounts, or communication strategies.
| Cluster | Customer Type | Marketing Strategy |
|---|---|---|
| Cluster 1 | Frequent high-spenders | Exclusive loyalty programs |
| Cluster 2 | Occasional buyers | Retargeting ads & seasonal coupons |
| Cluster 3 | Price-sensitive users | Budget-friendly bundles |
This approach improves customer retention and ROI — a key project type featured in Generative AI Training in Hyderabad, where learners apply clustering on e-commerce datasets.
2. Anomaly and Fraud Detection
Overview
In finance, cybersecurity, and manufacturing, Unsupervised Learning is used to identify outliers — data points that don’t conform to normal patterns.
These outliers may represent fraud, security threats, or equipment malfunctions.
Example Applications
- Banking: Detect unusual credit-card transactions.
- Manufacturing: Identify machine-sensor readings that indicate a fault.
- Healthcare: Flag abnormal patient records for deeper analysis.
| Method | Description |
|---|---|
| Isolation Forests | Isolate anomalies based on data partitioning. |
| DBSCAN | Detect sparse points (noise) away from dense clusters. |
| Autoencoder Reconstruction Error | Poorly reconstructed samples indicate anomalies. |
Since labeled “fraud” or “attack” data is rare, Unsupervised Learning provides the flexibility to uncover threats that supervised models might miss.
3. Recommender Systems
How It Works
Recommender engines analyze user behavior and preferences to suggest products, videos, or content.
Using association rule learning and matrix factorization, these systems group users with similar interests or discover frequent co-purchases.
Example
Netflix and Amazon use Unsupervised Learning to identify clusters of similar users and recommend shows or items that like-minded people have enjoyed.
Algorithms Commonly Used
- Apriori Algorithm for rule generation.
- FP-Growth for finding frequent patterns.
- Collaborative filtering (can be unsupervised or self-supervised).
Real-World Benefit
Improves personalization and user engagement without explicit feedback.
Students working on Generative AI Training in Hyderabad projects often integrate these methods into AI-driven recommendation systems.
4. Dimensionality Reduction for Visualization and Pre-Processing
Why It’s Important
Data scientists often work with high-dimensional datasets — thousands of features that are hard to visualize or analyze.
Unsupervised Learning techniques like PCA or t-SNE reduce dimensionality, making it easier to see patterns and prepare data for supervised models.
Practical Benefits
- Visualize clusters in 2D or 3D plots.
- Eliminate redundant features.
- Improve performance and reduce overfitting.
- Enable better interpretation of complex datasets.
Example
In genomics research, PCA can compress thousands of gene expression features into two principal components to reveal disease-related patterns.
This is one of the foundational skills covered in Generative AI Training in Hyderabad, especially in modules on Autoencoders and Variational Autoencoders (VAEs).
5. Document and Text Clustering in NLP
Overview
Text data is often unstructured and unlabeled. Unsupervised Learning helps organize and categorize large corpora by semantic similarity.
| Technique | Description |
|---|---|
| Word Embeddings + K-Means | Vectorize words or documents and group similar meanings. |
| Topic Modeling (LDA) | Discover hidden topics or themes in text corpora. |
| Hierarchical Clustering | Build taxonomies of articles or documents. |
Example Use-Cases
- Grouping similar news articles automatically.
- Organizing support tickets by issue type.
- Detecting themes in social-media sentiment data.
These applications form part of Generative AI workflows, where unsupervised text clustering supports language-model training and dataset preparation.
6. Image and Computer Vision Applications
Overview
In computer vision, labeling images manually is expensive.
Unsupervised Learning allows AI to learn visual patterns without labels, paving the way for automatic feature extraction and image grouping.
| Application | Description |
|---|---|
| Image Segmentation | Cluster pixels based on color/intensity to identify regions. |
| Object Discovery | Identify objects or patterns without pre-tagged categories. |
| Feature Learning via Autoencoders | Learn compressed visual features for later supervised tasks. |
Unsupervised feature learning is also the foundation of Generative Models like GANs (Generative Adversarial Networks), which students explore in Generative AI Training in Hyderabad.
7. Healthcare and Medical Research
Overview
Healthcare data such as MRI scans, gene sequences, and patient histories are vast and often unlabeled.
Unsupervised Learning can uncover hidden correlations or early signs of disease.
Examples
- Grouping patients based on symptoms to detect disease subtypes.
- Identifying outlier lab results that indicate early risk.
- Analyzing genetic data to find associations with medical conditions.
Benefits
- Enables personalized treatment.
- Assists in drug discovery through clustering of molecular data.
- Supports predictive diagnostics by combining patterns with supervised systems.
8. Industrial IoT and Predictive Maintenance
Concept
In smart factories and IoT environments, sensor data is continuously streamed from machines.
Unsupervised Learning detects subtle anomalies or drifts in this data, helping prevent costly equipment failures.
Techniques Used
- Clustering and Density Models to identify machine behavior profiles.
- Autoencoders to learn normal operation signatures.
- Anomaly Detection to trigger alerts when patterns deviate.
Example
A power-plant model might learn what “normal vibration patterns” look like for turbines.
When vibration patterns diverge, the system alerts engineers to potential issues — before a breakdown occurs.
9.Cybersecurity and Network Monitoring
Role of Unsupervised Learning
Cybersecurity teams leverage Unsupervised Learning to detect suspicious activity that traditional rule-based systems miss.
Use-Cases
- Identifying unusual login behaviors or access patterns.
- Clustering IP traffic to detect new attack types.
- Flagging anomalies in network flow data.
Algorithms
K-Means, DBSCAN, and Autoencoders are often used in self-learning security systems, making Unsupervised Learning indispensable for modern cybersecurity infrastructure.
10. Generative AI and Creative Applications
Overview
Perhaps the most exciting domain where Unsupervised Learning shines is in Generative AI — models that can create new images, text, music, and videos.
How It Works
Generative AI models (like GANs, VAEs, and Diffusion Models) first use Unsupervised Learning to understand the latent structure of data.
Once this internal representation is learned, the model can generate new, realistic samples that share the same characteristics.
| Industry | Example |
|---|---|
| Art & Design | AI-generated artwork and digital creativity. |
| Entertainment | Automated music or video generation. |
| Gaming | Procedural world or character generation. |
| Marketing | AI-generated ad copies and designs. |
This tight link between Unsupervised Learning and creativity is why Generative AI Training in Hyderabad focuses so heavily on understanding latent representation learning.
Conclusion
Unsupervised Learning stands as one of the most powerful pillars of Artificial Intelligence — the ability for machines to learn from unlabeled data and discover the hidden order within chaos. Unlike supervised methods that depend on predefined outcomes, Unsupervised Learning enables systems to find patterns, structures, and relationships without human intervention.
Through our exploration of its definition, key differences, core techniques, and real-world applications, it’s clear that Unsupervised Learning is more than a theoretical concept — it’s a practical engine for innovation. From clustering and dimensionality reduction to anomaly detection and feature learning, these methods allow organizations to extract value from the 90 % of data that remains unlabeled and unused.
In today’s world of big data and intelligent automation, Unsupervised Learning fuels countless breakthroughs:
- Businesses use it for customer segmentation and personalized marketing.
- Healthcare leverages it for disease pattern discovery and predictive diagnostics.
- Finance and cybersecurity depend on it for fraud and anomaly detection.
- Manufacturing and IoT rely on it for predictive maintenance.
- And in the realm of Generative AI, Unsupervised Learning forms the foundation for creativity — enabling machines to generate realistic images, text, and even human-like ideas.
That’s why top institutions and platforms offering Generative AI Training in Hyderabad emphasize Unsupervised Learning as a cornerstone skill. It empowers learners to build models that don’t just predict — they perceive. By mastering these techniques, students gain the ability to uncover hidden insights, design smarter AI systems, and contribute to next-generation innovations.
In essence, Unsupervised Learning bridges data and discovery — transforming information into intelligence and creativity into computation. Whether you’re an aspiring data scientist, a researcher, or a tech innovator, embracing Unsupervised Learning is not just about understanding algorithms; it’s about shaping the future of AI itself.
FAQ'S
What is Unsupervised Learning?
Unsupervised Learning is a type of machine learning that analyzes unlabeled data to find hidden patterns or relationships. It allows algorithms to organize data without human-provided answers or categories.
How does Unsupervised Learning differ from Supervised Learning?
In Supervised Learning, models learn from labeled datasets to predict outcomes.
In Unsupervised Learning, there are no labels — the algorithm identifies clusters, correlations, or structures within the data on its own.
What are the main techniques used in Unsupervised Learning?
Popular techniques include:
- Clustering (K-Means, Hierarchical, DBSCAN)
- Dimensionality Reduction (PCA, t-SNE, Autoencoders)
- Association Rule Learning (Apriori, FP-Growth)
- Anomaly Detection and Feature Learning
These are key concepts in Generative AI Training in Hyderabad programs.
What are the real-world applications of Unsupervised Learning?
It is used in many industries, including:
- Marketing: Customer segmentation
- Finance: Fraud detection
- Healthcare: Disease pattern discovery
- Cybersecurity: Intrusion and threat detection
- Generative AI: Content creation and data synthesis
Why is Unsupervised Learning important in Generative AI?
Generative AI models like GANs and VAEs depend on Unsupervised Learning to understand data structure and create new, realistic outputs. It enables AI to learn patterns first and generate creative results later.
What are the advantages and limitations of Unsupervised Learning?
Advantages:
- Works with unlabeled data.
- Reveals hidden patterns and insights.
- Useful for exploratory analysis.
Limitations:
- Harder to evaluate accuracy.
- May produce ambiguous or meaningless clusters.
- Requires expert interpretation.
Is Unsupervised Learning part of Generative AI Training in Hyderabad?
Yes Most Generative AI Training in Hyderabad courses include Unsupervised Learning modules covering clustering, dimensionality reduction, and feature discovery — helping learners build the foundation for real-world AI and data science applications.